Rich Text on the Web in 2018
July 4, 2018
If you’re building a web app that allows users to write free-form text in 2018, it’s very likely that you’ll come upon the need to present that text with various formatting options like bold or italic, so called rich text. In fact, I’d wager to say that it’s almost a requirement to have some kind of rich text editing interface for any kind of business-user-facing web app because it’s such a universally needed feature.
Dealing with rich text on the web is an interesting problem, but it’s interesting because it’s…well, uninteresting. Users have been inputting rich text for years in word processors like Microsoft Word, so the interaction details are somewhat known and established. There’s not much in the way of exciting, modern UX to build here, so in that sense it’s a little uninteresting. In that same sense, though, it’s also a win. Anytime you can build a web experience that users already know how to use and lets them get stuff done is a good thing in my opinion.
However, just because it’s fairly established as a UX pattern doesn’t mean it’s completely solved as an implementation. It’s been my personal mission the last few weeks to solve this problem for an app we’re building at HelloSign, so I’ve been deep in the weeds of this topic. During my research I found lots of good content on the surface-level implementation details, like which libraries are out there and the various techniques for building a rich text editor component. But I found it difficult to find information on some of the deeper, more practical problems that I was facing, like:
- How do I store this in my database?
- How do I handle both the editing and displaying of the rich text in different contexts? Are those two concepts the same thing?
- What about things like “mentions” that’s not really just text?
- What about security?
So I thought I’d write a bit about those particular aspects. This won’t be an article about the specifics of building a rich text editor, although I may add one of those next!
What is rich text and why is it difficult?
Before going further it’s probably best to give some context on what exactly I mean when referring to rich text. Here’s a quick screen shot of a rich text editor from Atlassian’s component library:
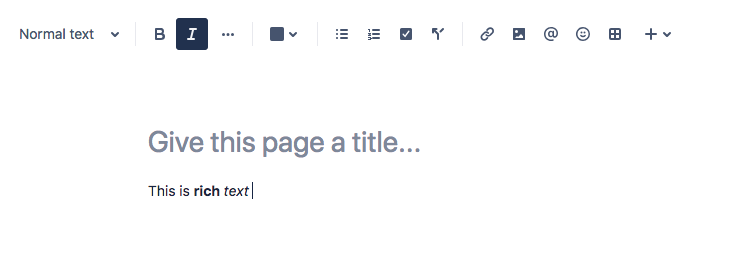
The way I think about rich text is that it’s plain text with additional structural and formatting information attached directly to it. I also think of rich text as having a few different vantage points:
- From the perspective of the user, it’s just text that’s visually displayed with the chosen formatting (we’ll get to things like “mentions” later).
- From the perspective of the browser, it’s HTML. This may seem obvious, but I find it helpful to call it out in order to distinguish this point of view from the next one.
- From the perspective of the developer, it’s data. Ultimately, rich text cannot be represented with just text, so it needs to be represented as some sort of data structure. This could also be HTML but it could also be another format, like JSON or markdown. More on that later.
Having these three perspectives helped me work towards a solution that fit my needs but it also highlights why this problem can be a difficult one to solve. Like most problems in web development, I found that there was really no one “correct” solution. Each piece of the solution relied on various aspects of my own particular needs. Trade offs were made.
For me, I found a few of the core considerations for the problem to be:
- What kind of content will users be allowed to enter?
- What are all of the rendering contexts that need to be supported?
- How will security be handled?
- What other processes need to interact with the rich text content?
Continuing to ask these core questions along the way in my research helped me work towards a reasonable (I hope 😬) solution.
Database storage
Before moving forward with much else, I wanted to have an idea of the kinds of inputs and outputs I’d be dealing with and how I’d store and retrieve those values from the database. There were a few options that I’d found being used in the community.
HTML
Most WYSIWYG (what-you-see-is-what-you-get) editors of the past worked strictly with HTML. Meaning, you start with a blob of HTML and you get out a blob of HTML. An example would be an editor like TinyMCE or CKEditor. This makes plenty of sense and existing libraries still do this today. After all, HTML is the language of the web. It’s a standardized, familiar syntax that’s easily interoperable with anything that can understand HTML.
Storing the rich text value as HTML would mean storing a text value like this:
<p>Open the console to see the <em>html.get</em> method working.</p>
<p><span style="font-size: 18px;">HELLO</span></p>
<p>
<span style="font-size: 18px;"
><a href="https://google.com">GOOGLE LINK</a></span
>
</p>
<p><br /></p>If you’re at all security-minded, storing user-generated HTML probably sets
off some red flags. Anytime you are storing user-generated content with the intent
of rendering that content back out on the screen, you are vulnerable to XSS (Cross-site-scripting)
attacks. Technically while any user-generated content is vulnerable to this, I
feel it’s particularly relevant when dealing with rich text stored as HTML because
it’s likely that it will be rendered back out as HTML (e.g. element.innerHTML = storedHTML) which is where XSS usually
comes in to play.
That said, storing HTML is perfectly valid and is still used today. There is a way to handle it that’s reasonable safe. A general strategy could be to sanitize the generated HTML for XSS concerns and use a whitelist approached to strip out anything that you deem not appropriate. There are plenty of libraries that do this (DOMPurify is one). And note that you usually want to do this on both inputs and outputs, so sanitize on the server before saving to the database and before rendering to the screen. This will give you a reasonably safe implementation, but some security devs may still not love it. Storing HTML in the database can feel a bit like a ticking time bomb that can blow up some point way in the future if you forget to follow one of the security steps when saving or rendering.
A few interesting points I noticed about using HTML to store rich text values:
It’s very powerful for styling options
This can be seen as either a good thing or bad thing. In the example above, to
be able to display a custom font size the font-size property is added:
<span style="font-size: 18px">words</span>This gives the client a pretty powerful mechanism for generating the exact visual representation that it wants without much room for interpretation. This could be a good thing if you need users to be able to expressive lots of different visual formatting and you just want to retrieve this value from the database and drop into an HTML page. However, there could be a case to be made that it’s too powerful. The client could generate this:
<span style="font-size: 3000px">words</span>It’s unlikely clients need the power to render font sizes at 3000 pixels!
It’s a more literal representation of the contents
The HTML generated in the example above is a very literal representation of the contents. Meaning, it represents text with exactly a font size of 18 pixels. If you’re only rendering within the context of web browsers and you want to be able to stick the generated content on a page and be done with it, this can be a good option. However I find that in some cases it can be better to leave yourself with room to evolve your UI. For example, instead of saving a literal font size value maybe you save something like this:
<span class="f-1">words</span>In most cases, that’s probably not what you want. Sure you can validate this on both the client and the server, but it may become difficult to keep up with all of the different ways HTML can make for some horrible looking web pages.
Similar to how you might style a regular webpage, you likely don’t style with exact pixel values but instead style with classes that represent relative values that you can evolve and change over time. It also could allow you to represent that text differently for different rendering contexts if you need to. For example, maybe you’re rendering to a PDF that uses a different font family so the pixel value needs to be slightly different.
Exploring the idea of storing my rich text as HTML began to highlight the fact that there is a difference between storing the literal content of the rich text and storing a description of the rich text. For my use case, I wanted pretty tight control over how my rich text rendered and even had different eventual rendering targets (more on that later), so I realized that if I were to use HTML I would essentially be using HTML as a data format. Meaning, I likely wouldn’t allow just any HTML to be stored, it would be a controlled subset with a specific structure that I could potentially render in different ways to different targets. In fact, there’s a good article by one of the project leads for CKEditor that describes using HTML as the data format for rich text: A Standard for Rich-Text Data.
Markdown
To take a step back from HTML, my first thought for an MVP-like solution to this problem was to support Markdown. Markdown is a fairly well-known syntax for doing basic formatting. It’s used on developer-centric sites like Github and StackOverflow. Markdown is a nice solution because it avoids a few of the security issues (but not all!) with HTML and doesn’t require any kind of special client-side components to work with. It’s still plain text when it’s entered by the user and only turned into HTML when saved to the database or rendered to the browser. The syntax is small and relatively standardized so it’s likely there will be plenty of existing libraries to choose from that can take Markdown and spit out HTML.
The issue with Markdown is that, by design, only supports a very limited set of formatting. If you’re just doing bold and italic formatting, then Markdown will work just fine. If you’re doing anything more complex, like colors or font families, then vanilla Markdown won’t help you. There are some extensions and “flavors” to Markdown for extending the syntax, but at that point I think Markdown starts to lose a little bit of its original value. Markdown is not really meant to do much more than basic formatting. Anything outside of basic formatting and Markdown yields to just allowing arbitrary HTML, in which case you’re back to dealing with all of the points mentioned in the above section.
I like the idea of Markdown and I think it makes sense if you’re able to stick with basic formatting.
JSON
If you’ve decided that you want to store a description of your rich text data to your database, JSON seems like a natural choice. In fact, many modern rich text editors represent their contents not with HTML but with a custom data structure that can be easily serialized to JSON. QuillJS has a Delta format, ProseMirror has a Document, and DraftJS has its own EditorState.
Based on what we’ve discussed so far, here are some good things about storing rich text as JSON:
- It’s more secure against XSS by default. You can’t just pass a string of JSON and render it as HTML.
- It can represent any kind of content and formatting you might need
- It can be easily parsed, validated, and manipluated by almost any system
- It’s a description of the content, so it can be rendered differently to different targets
Those good things also come with some downsides:
- No standardization. There is no one JSON format for rich text. Each library implements their own version which can lead to lock-in
- More code. Because you can’t just render JSON to HTML, that means you need to write code that knows how to do that.
JSON can be a good option for any reasonably complex rich text editor needs if you’re willing to write more code. A way of dealing with library and JSON format lock-in is to make sure you a strategy for migrating and making changes over time. Using a JSON Schema definition with a version number is a good way to do that.
There are also explorations into standard-ish formats for representing rich text. Mobiledoc and Portable Text are two that I’ve seen in this area.
Rendering outside of the editor
Another interesting consideration when thinking about rich text is where you’re going to need to render that rich text. In some cases, you only need it in the context of an editor. Something like Dropbox Paper or Google docs is an example. You only ever pull that rich text up in the editor so you can be free to optimize for that rendering target. But in some cases you have both the editing context and the rendering context. For example, you may be editing rich text in the admin section of a blog, saving it to the database, and then rendering it back out on a completely separate page. In those cases, you need a way to render that rich text to the screen directly from the database. HTML has an advantage here because it can just be rendered directly. JSON must be encoded to HTML somehow first. Some solutions to this require that a read-only instance of a rich text editor be loaded up to render the custom JSON format. I’ve found most rich text libraries to be pretty heavy so in my opinion this is not ideal. However, a JSON format that is simple enough can be fairly easily encoded into HTML without the need for the entire editor library. This also can help negate some of the security issues with rendering user-generated content. A controlled “renderer” will only render the things it knows about and likely will be rendering actual user content as text, not HTML.
Summary
There’s probably a lot more I could say about rich text. I found it to be a deep, challenging, and, at times, overwhelming topic for a seemingly universal need for most web apps. For my own use, I ended up going with ProseMirror but it’s not without its own tradeoffs.
Thanks
Big thanks to Atlassian for their open-source code in AtlasKit which was a great help in seeing how a real-world rich text eidtor could be built.